 De nuevo, como necesidad de unos de los programas que tuve que escribir hace un tiempo, surgió el problema de enviar mensajes de correo electrónico desde un programa en C++.
De nuevo, como necesidad de unos de los programas que tuve que escribir hace un tiempo, surgió el problema de enviar mensajes de correo electrónico desde un programa en C++.
De nuevo, me puse a buscar por Internet, con resultados decepcionantes, en la mayoría de los casos.
La opción más simple es usar MAPI (Messaging Application Programming Interface), pero esto tiene como consecuencia directa que se usa la aplicación de correo instalada en Windows como pasarela. Esto provoca algunos inconvenientes, al menos para la aplicación que estaba desarrollando.
- En mi caso, la aplicación de correo era Outlook. Para evitar el envío de correos de forma indiscriminada, lo cual está bien, Outlook muestra un cuadro de diálogo cada vez que se intente enviar un mensaje desde fuera de él. Esto era un inconveniente en mi caso, ya que la aplicación debía funcionar automáticamente, de modo desatendido, es decir, sin la presencia de un usuario.
- Los mensajes enviados de este modo permanecen en la carpeta de mensajes enviados. Esto es un problema menor, o incluso, ni siquiera es un problema.
- Los mensajes se envían usando el servidor de correo por defecto para la cuenta de Outlook.
En mi caso concreto, el mayor inconveniente era el primero, pero no hay que descartar los otros problemas y otros que se me hayan podido pasar por alto.
Lo que buscaba era una forma de enviar correos independiente de las aplicaciones instaladas en el PC, y que funcionase incluso sin una aplicación de correo instalada.
La solución que más me gustó fue usar la librería Blat, (BLAT.DLL). Como siempre, por simplicidad, ya que requiere poca instalación (sólo una DLL), y es fácil de utilizar, al menos relativamente fácil.
Tengo que aclarar que la aplicación de la que hablo no se dedica a hacer spam, aunque pueda parecer lo contrario. Es más, espero que nadie use esta guía con esa finalidad. En la página de Blat advierten sobre el mismo tema. Por supuesto, no me hago responsable del uso que cada uno haga de esta guía, pero si la usas para actividades de legalidad dudosa, al menos no me menciones como fuente.
Descargar Blat
Existe una página dedicada al proyecto Blat: www.blat.net desde la que se puede descargar la última versión, ya sea para 32 ó 64 bits. En el momento que escribo esta entrada, la última versión es la 3.11, y usaré la versión de 32 bits.
Para descargar los ficheros necesarios basta con pulsar la opción «Download», que nos lleva a la página del proyecto en SourceForge, y donde podremos elegir la versión que mejor nos parezca. Para los ejemplos usaremos la versión completa, y no el código fuente.
El fichero zip que descargaremos contiene dos carpetas: docs y full.
La primera contiene información sobre la librería: historial de versiones, créditos, términos de licencia y sintaxis.
La segunda es la que más nos interesa, y contiene los siguientes ficheros:
- blat.exe: programa para línea de comandos que permite enviar mensajes de correo.
- blat.dll: librería de enlace dinámico, para usar blat desde nuestros programas en C/C++.
- blatdll.h: fichero de cabecera para incluir en nuestros proyectos.
- blat.lib: librería estática para poder enlazar con la dinámica.
El primer inconveniente, si el compilador que usamos es Mingw/GCC, es que la librería estática no nos sirve. Puedes consultar la entrada de cómo convertir librerías LIB a formato A para evitar este problema.
Después de obtener el fichero «libblat.a», lo copiaremos a la carpeta «lib» de Mingw. También tenemos que hacer que el fichero blatdll.dll sea accesible, bien haciendo que esté en la misma carpeta que nuestro programa ejecutable, o bien copiándolo en una carpeta cuya ruta esté incluida en el PATH.
Una vez hecho esto, ya podremos usar la DLL en nuestro programa.
Sintaxis
Para nosotros, la única función de la librería que nos interesa es Send, que sólo tiene un parámetro, en forma de cadena de caracteres terminada en nulo.
Esta sintaxis es engañosamente simple, ya que la sintaxis de la cadena que usaremos como argumento es bastante complicada.
La cadena consta varios parámetros, cada uno de los cuales está formado por dos cadenas. La primera, que siempre empieza con un ‘-‘ indica el nombre del parámetro, y la segunda el valor.
Hay muchos parámetros, pero no voy a exponerlos todos aquí, sólo aquellos imprescindibles para enviar mensajes con ficheros adjuntos.
Relativos al servidor de correo
Esta librería no funciona como un servidor de correo, sino que usa una cuenta existente en un servidor de correo electrónico en Internet. Por lo tanto, necesitamos tener acceso a una cuenta de correo, sus parámetros y contraseña. Puede ser un servidor SMPT o NNTP.
-server <addr> : especifica el servidor SMTP a usar (opcionalmente, addr:port)
-serverSMTP <addr> : lo mismo que -server
-serverNNTP <addr> : especifica el servidor NNTP a usar (opcionalmente, addr:port)
-serverPOP3 <addr> : especifica el servidor POP3 a usar (opcionalmente, addr:port) cuando se requiera un acceso POP3 antes de enviar un email
-serverIMAP <addr> : especifica el servidor IMAP a usar (opcionalmente, addr:port) cuando se requiera un acceso IMAP antes de enviar un email
-f <sender> : ignora la dirección de remite por defecto (debe ser conocida para el servidor)
-i <addr> : una dirección de origen (‘From:’), no necesariamente conocida por el servidor
-port <port> : puerto a usar por el servidor SMTP, por defecto para SMTP (25)
-portSMTP <port>: lo mismo que -port
-portNNTP <port>: puerto a usar por el servidor NNTP, por defecto para NNTP (119)
-portPOP3 <port>: puerto a usar por el servidor POP3, por defecto para POP3 (110)
-portIMAP <port>: puerto a usar por el servidor IMAP, por defecto para IMAP (110)
-u <username> : nombre de usuario para AUTH LOGIN (usar con -pw) o para AUTH GSSAPI con -k
-pw <password> : contraseña para AUTH LOGIN (usar con -u)
-pu <username> : nombre de usuario para POP3 LOGIN (usar con -ppw)
-ppw <password> : contraseña para POP3 LOGIN (usar con -pu)
-iu <username> : nombre de usuario para IMAP LOGIN (usar con -ppw)
-ipw <password> : contraseña para IMAP LOGIN (usar con -pu)
-k : Use UNKNOWN mutual authentication and AUTH GSSAPI
-kc : Use UNKNOWN client-only authentication and AUTH GSSAPI
-service <name> : Set GSSAPI service name (use with -k), default «smtp@server»
-level <lev> : Set GSSAPI protection level to <lev>, which should be one of: None, Integrity, or Privacy (default GSSAPI level is Privacy)
-nomd5 : Do NOT use CRAM-MD5 authentication. Use this in cases where the server’s CRAM-MD5 is broken, such as Network Solutions.
Direcciones de destino
-to <recipient> : recipient list (also -t) (comma separated)
-cc <recipient> : carbon copy recipient list (also -c) (comma separated)
-bcc <recipient>: blind carbon copy recipient list (also -b)
-ur : set To: header to Undisclosed Recipients if not using the
-to and -cc options
-subject <subj> : subject line, surround with quotes to include spaces(also -s)
-ss : suppress subject line if not defined
-body <text> : message body, surround with quotes («) to include spaces
Ficheros adjuntos
-attach <file> : attach binary file(s) to message (filenames comma separated)
-attacht <file> : attach text file(s) to message (filenames comma separated)
-attachi <file> : attach text file(s) as INLINE (filenames comma separated)
-embed <file> : embed file(s) in HTML. Object tag in HTML must specify
content-id using cid: tag. eg: <img src=»cid:image.jpg»>
-af <file> : file containing list of binary file(s) to attach (comma
separated)
-atf <file> : file containing list of text file(s) to attach (comma
separated)
-aef <file> : file containing list of embed file(s) to attach (comma
separated)
-base64 : send binary files using base64 (binary MIME)
-uuencode : send binary files UUEncoded
-enriched : send an enriched text message (Content-Type=text/enriched)
-unicode : message body is in 16- or 32-bit Unicode format
-html : send an HTML message (Content-Type=text/html)
-alttext <text> : plain text for use as alternate text
-alttextf <file>: plain text file for use as alternate text
-mime : MIME Quoted-Printable Content-Transfer-Encoding
-8bitmime : ask for 8bit data support when sending MIME
-multipart <size>
: send multipart messages, breaking attachments on <size>
KB boundaries, where <size> is per 1000 bytes
-nomps : do not allow multipart messages
-contentType <string>
: use <string> in the ContentType header for attachments that
do not have a registered content type for the extension
For example: -contenttype «text/calendar»
Parámetros menos frecuentes
-organization <organization>
: Organization field (also -o and -org)
-ua : include User-Agent header line instead of X-Mailer
-x <X-Header: detail>
: custom ‘X-‘ header. eg: -x «X-INFO: Blat is Great!»
-noh : prevent X-Mailer/User-Agent header from showing Blat homepage
-noh2 : prevent X-Mailer header entirely
-d : request disposition notification
-r : request return receipt
-charset <cs> : user defined charset. The default is iso-8859-1
-a1 <header> : add custom header line at the end of the regular headers
-a2 <header> : same as -a1, for a second custom header line
-dsn <nsfd> : use Delivery Status Notifications (RFC 3461)
n = never, s = successful, f = failure, d = delayed
can be used together, however N takes precedence
-hdrencb : use base64 for encoding headers, if necessary
-hdrencq : use quoted-printable for encoding headers, if necessary
-priority <pr> : set message priority 0 for low, 1 for high
-sensitivity <s>: set message sensitivity 0 for personal, 1 for private,
2 for company-confidential
Ejemplo C++
Veamos un ejemplo sencillo que envía un mensaje de texto con dos adjuntos:
#include <iostream>
#include <windows.h>
#include <cstdio>
#include "blatdll.h"
using namespace std;
int main()
{
char cad[128];
ULONG err;
char nombre[2][256];
char remiteCorreo[64];
char servidorCorreo[64];
char usuarioCorreo[64];
char passwordCorreo[64];
char asuntomsg[256];
char textomsg[1024];
char cmdline[4096];
char szTo[64];
char szCc[64];
char szCo[64];
strcpy(remiteCorreo, "<usuario@servidor>");
strcpy(servidorCorreo, "<servidor.de.correo>");
strcpy(usuarioCorreo, "<usuariodecorrreo>");
strcpy(passwordCorreo, "<contraseña>");
sprintf(nombre[0], ".\\main.cpp"); // Ruta de acceso del 1er fichero
sprintf(nombre[1], ".\\blatdll.h"); // Ruta de acceso del 2º fichero
sprintf(asuntomsg, "mensaje enviado usando Blat");
sprintf(textomsg, "Cuerpo del mensaje.\nRealizando prueba.\n-- \nConClase\n");
sprintf(cmdline, "-body \"%s\" -q -f %s -server %s -u %s -pw %s -attach %s,%s -base64 -subject \"%s\"",
textomsg, remiteCorreo, servidorCorreo, usuarioCorreo, passwordCorreo, nombre[0], nombre[1], asuntomsg);
cout << cmdline << endl;
// Añadir direcciones To:
strcpy(szTo, " -to <direccion_destino>");
strcat(cmdline, szTo);
strcpy(szCc, " -cc <direccion_copia>");
strcat(cmdline, szCc);
strcpy(szCo, " -bcc <direccion_copia_oculta>");
strcat(cmdline, szCo);
err = Send(cmdline);
switch(err) {
case 0:
sprintf(cad, "Mensaje enviado");
break;
case 1:
sprintf(cad, "Error de conexión o dirección de destino erronea.");
break;
case 2:
sprintf(cad, "Conexión denegada o dirección de remite erronea.");
break;
default:
sprintf(cad, "Error %ld", err);
break;
}
cout << cad << endl;
if(err) return -1;
return 0;
}
Bastará con sustituir los textos entre <> por lo adecuados en tu caso.
 ¿Cómo podemos evitar que una aplicación se ejecute más de una vez de forma simultánea?
¿Cómo podemos evitar que una aplicación se ejecute más de una vez de forma simultánea? A veces puede ser interesante que nuestras aplicaciones coloquen un icono en el área de notificación.
A veces puede ser interesante que nuestras aplicaciones coloquen un icono en el área de notificación.
 En las últimas versiones de PHP, el soporte para programación orientada a objetos mejoró considerablemente. A día de hoy, que cualquier proyecto medianamente complejo desarrollado en PHP esté basado en POO es prácticamente una necesidad.
En las últimas versiones de PHP, el soporte para programación orientada a objetos mejoró considerablemente. A día de hoy, que cualquier proyecto medianamente complejo desarrollado en PHP esté basado en POO es prácticamente una necesidad. Con cierta frecuencia encontramos bibliotecas (o librerías) de funciones que nos pueden resultar útiles en nuestros programas. En este blog hablaremos de algunas de ellas.
Con cierta frecuencia encontramos bibliotecas (o librerías) de funciones que nos pueden resultar útiles en nuestros programas. En este blog hablaremos de algunas de ellas.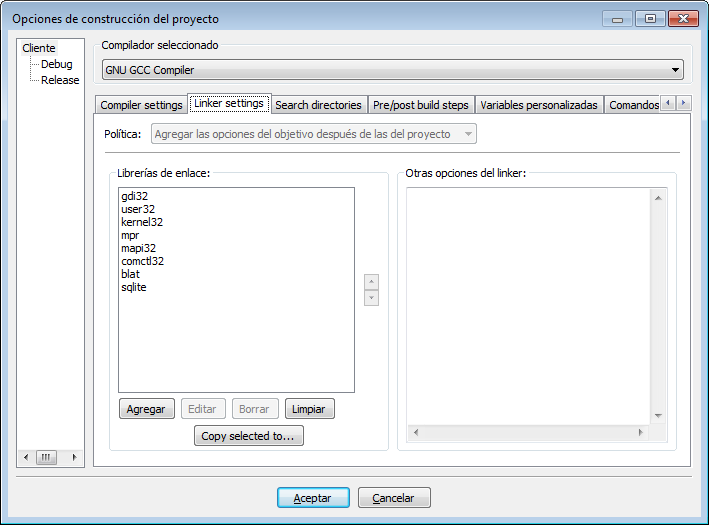
 Hace unos meses me encontré con la necesidad de acceder a ciertos ficheros desde una aplicación C++.
Hace unos meses me encontré con la necesidad de acceder a ciertos ficheros desde una aplicación C++.